Vid-ODE: Continuous-Time Video Generation
with Neural Ordinary Differential Equation
AAAI 2021

Abstract
Video generation models often operate under the assumption of fixed frame rates, which leads to suboptimal performance when it comes to handling flexible frame rates (e.g.,increasing the frame rate of more dynamic portion of the video as well as handling missing video frames). To resolve the restricted nature of existing video generation models’ ability to handle arbitrary timesteps, we propose continuous-time video generation by combining neural ODE (Vid-ODE) with pixel-level video processing techniques. Using ODE-ConvGRU as an encoder, a convolutional version of the recently proposed neural ODE, which enables us to learn continuous-time dynamics, Vid-ODE can learn the spatio-temporal dynamics of input videos of flexible frame rates. The decoder integrates the learned dynamics function to synthesize video frames at any given timesteps, where the pixel-level composition technique is used to maintain the sharpness of individual frames. With extensive experiments on four real-world video datasets, we verify that the proposed Vid-ODE outperforms state-of-the-art approaches under various video generation settings, both within the trained time range (interpolation) and beyond the range (extrapolation). To the best of our knowledge, Vid-ODE is the first work successfully performing continuous-time video generation using real-world videos.
Paper and Supplementary Material

Method overview
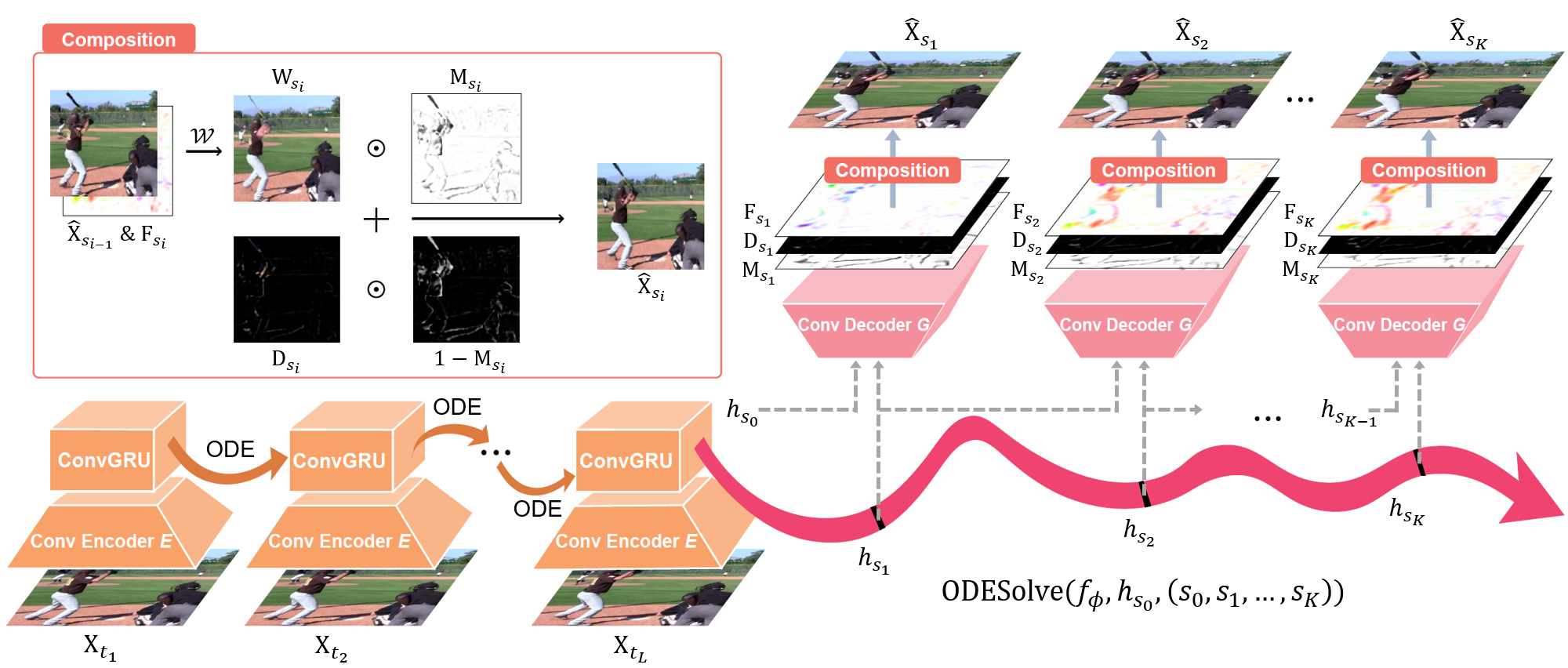
Additional Results



